今天是行程的第五天,這天主要在池袋玩 VR。
早上起來的時候已經不早了,我們先到池袋車站,由西口走向東口。
東口那邊的食店比較多。行行逛逛,找到了一家有燒肉放題的餐館。午餐3000多日元就可以吃到了放題,看到後我們便進去了。
吃過午餐後,我們便到了 Sunshine City。

對 Sunshine City 的印象,是有一家店專賣史努比用品的。那邊的商場比較像商業中心,初初也迷路了。後來在升降機的大堂側,找到了商場的入口。
那個商場很大,有很多遊客,也有很多賣少女服飾的店。太太看到當然要閑逛一番。
裏面有一家店是賣迪士尼玩具及精品的,有一隻超巨型的維尼熊。維尼熊是望向門口的,突然太太大叫了一聲。你看看那邊。然後筆者便望向太太指著的方向,看到那隻巨型小熊維尼,正在向我們揮手。嚇得我目定口呆。屌你老味原來有個女職員喺後面,玩緊佢隻手。非常搞笑。

再走到三樓處,在最裏面的地方,我們看到了一家,沒有開燈的店鋪。那店舖像是給兒童遊玩的兒童遊樂園。店面的面積是超巨大的。
在四樓的相同地方我們看到了一所 VR 電玩中心。和太太商量了一會之後,決定進去看看。在詢問價格後,就去到門票處準備買票。在那裏有位女店員,原來是從香港來的。在異地能聽到廣東話真的很親切。她介紹我們買最貴的套票,因為最貴的套票可以玩足所有遊戲,如果時間許可是十分值得的。
對於今天沒有什麼景點跑的我們來講。是一個非常合適的時光。4100日元 1 位。
場內真的有很多不同的電玩遊戲。有孖寶賽車,食鬼,高爾夫球,密室逃脫,哥斯拉,高達,等等。當中孖寶賽車及哥師奶是非常好玩的。

其中有一個是要逃脫密室的,叫作逃脫病棟。那個遊戲是玩家坐在一張輪椅上,然後你手上祇有一支電筒,你便要和其它的玩家協作。一起選擇正確的路然後逃出醫院。途中會有很多已變成喪屍的醫護人員出來嚇你。非常驚嚇但也十分搞笑。
另外有一個遊戲,是玩家乘坐在吉普車上,拿著槍對付喪屍。筆者和太太分別坐在吉普車的前座左右,各拿手槍面向喪屍。遊戲的目的是不能被喪屍碰到,如果喪屍碰到你的身體便會遊戲失敗。
在遊戲中途有大量的喪屍從筆者那邊跑出來,然後瘋狂被爪數十下我看那時已經命喪在車子上了,但是喪屍找了我之後卻沒有立即把我變成喪屍。慢慢喪屍便被我一隻一隻擊殺,此時我看到太太的那邊是沒有喪屍走出來的。我在驚訝著為什麼太太那邊那麼易玩。
然後劇情繼續下去,是吉普車會墮入一個黑洞之中。躲進去後我看到吉普車的司機已經死了。然後我望向太太的方向,他的牙已經變成尖,而且手還有鮮血皮膚變成紫色,那時我確定她已經變成喪屍了。不出一會,他便醒來然後,撲向我瘋狂地咬。我的遊戲便輸了。
當我除眼罩後還怪責太太沒有打好喪屍類他變成喪屍然後咬死我。但原來在他的遊戲內他是勝出了,三人也不能夠成功逃脫。然後我問他,你不是那邊沒有喪屍嗎。他對我說你那邊才沒有喪屍他那邊的喪屍是超多的。我才知道原來每個玩家換的也是獨立故事。
遊戲實在太多了,沒有逐一把它們玩完便要離開。那時已經差不多晚上十時,遊戲也要關機了。我們回到商場內,大部份的店鋪已經落閘。我們的肚子也餓得發出聲響了。
離開店舖後便出發找吃的東西,在東口的商場實在太多夾公仔店舖了。當然太太又忍不住,去夾了兩隻角落生物回來。使用了500日元。
在東口一直行我們到了一家在地底的居酒屋。這家居酒屋,先前太太在旅遊書有介紹過說東西很不錯價錢也便宜,所以我們便決定進食。這次我們拍了很多照片。





吃過晚飯後已經夜深了,在池袋的街頭依然是非常多人,但感覺比名古屋好像安全得多,起碼沒有一群群的人在街角吸煙。
很快便回到飯店休息,這天行程完結。
今天是行程的第四天,因為今天有會朋友先回家的關係,而她乘坐的 NEX 開出地點是新宿站,所以今天我們會到新宿走走。
像我這種年齡的香港人對新宿的印象大概會記得的是成龍的電影 '新宿事件'。那套電影的主要場景就是日本東京的新宿區,有關歌舞技町的黑幫事件。

今天親身來到新宿可是看不到當年電影內的氣氛,只是感覺到熱熱的氣天及滿滿行人。

行了一會吃過午餐後就到了夾公仔店去瘋狂夾公仔了 !!!
已經過了不知多久,朋友的 NEX 時間也差不多到了。我們先回到新宿站找回寄放行李的 LOCKER 再去乘車。
可怕的事情發生了 !! 就是找不到寄放行季的地方,找了很久也找不到。結果朋友說她自己行季便好。最後她自己找到了呢 !! 十分利害。(新宿的車站真的超級大及很多鐵路交匯)
和她分別後筆者和太太便在新宿站乘 JR 到秋葉原站,準備去血併一番。

這裡的 SEGA 店真是超大規模的,有分為 1 2 3 4 5 座,每坐都會有 4-5層。有夾公仔的,也有是街機遊戲。

行了幾家館已經用了很多氣力。晚餐在一號館旁邊有一所在地下 B1 的餐館用餐,進去那時候時間還早 ( 大約 6 時 ),那時候沒有人在排隊,但在出餐館時已經有十多人在門外排隊 !!
店家弄的東西十分好吃,是鐵板牛肉飯 (忘記了拍照)。
吃飽後再走一會就乘坐 JR 回池袋了,真的很累。
### TL;DR
Please visit: https://www.sslforfree.com

### SSL
Nowadays an SSL certification for your web site is a must. And now you may not pay for an SSL certificate for your web site. With SSL For Free, it will generate a valid SSL certificate for your domain name. Even Wildcard SSL Certificates are also free.
Steps are easy:
1. Go to https://www.sslforfree.com
2. Enter your domain name into the text input field
3. Hit 'Create Free SSL Certificate'
4. There are three types of domain validation method :
- Automatic FTP Verification
- Manual Verification
- Manual Verification (DNS)
Choose any one of them to verify the domain name is owned by you.
5. Finally, an SSL certificate will issue.
6. Install the SSL certificate to your web application server.
來到行程的第三日,今日會去到東京最多人 (筆者覺得最多人) 的地方,原宿和涉谷。
因為實在太多人的關係,所以連相都沒有拍太多,主要是到了城市中的一個城堡!
明治神宮
明治神宮的介紹 : https://tokyo.letsgojp.com/archives/52391
我們由池袋坐 JR 到原宿站,由南口出站先到表參道行一圈。那邊都要商場及賣場等等。一定能夠滿足女士的行街需要。
先後就開始向明治神宮出發。

這裡超多人在拍照,因為那天天氣實在太熱了。在一大片的陽光下地面的溫度非常高,在有大量樹陰的小型森林中特別涼快。


有個外國的旅行團來拍照。
這個鳥居真的非常的大,那個木柱大約要 3-4 個成年人手拉手才能環抱。






之後去的地方實在太像太多人,所以沒有拍太多照了。
> 原文網址 : https://www.vpsee.com/2010/08/block-traffic-from-a-specific-country-using-iptables/
星期六我們一位客戶受到攻擊,我們的網絡監測顯示有連續6小時的巨大異常流量,我們立即聯係了客戶,沒有得到回應,我們修改和限製了客戶的 VPS,使得個別 VPS 受攻擊不會對整個服務器和其他 VPS 用戶造成任何影響,我們一直保持這個 VPS 為開通狀態(盡管一直受攻擊),攻擊又持續了24小時,星期天攻擊仍在繼續,我們忍無可忍,但是仍然無法聯係到客戶,我們向客戶網站的另一負責人詢問是否需要我們介入來幫助解決,這位負責人答應後我們立即投入到與 DDoS 的戰鬥中(我們動態掃描屏蔽壞 IP,現在客戶網站已恢複。整個過程很有意思,以後有時間再寫一篇博客來描述)。登錄到客戶 VPS 第一件事情就是查當前連接和 IP,來自中國的大量 IP 不斷侵占80端口,典型的 DDoS. 所以第一件事是切斷攻擊源,既然攻擊隻攻80端口,那有很多辦法可以切斷,直接關閉網站服務器、直接用防火牆/iptables 切斷80端口或者關閉所有連接、把 VPS 網絡關掉、換一個 IP,⋯,等等。因為攻擊源在國內,所以我們決定切斷來自國內的所有訪問,這樣看上去網站好像是被牆了而不是被攻擊了,有助於維護客戶網站的光輝形象:D,那麼如何屏蔽來自某個特定國家的 IP 呢?
方法很容易,先到 [IPdeny](http://www.ipdeny.com/ipblocks) 下載以國家代碼編製好的 IP 地址列表,比如下載 cn.zone:
```sh
# wget http://www.ipdeny.com/ipblocks/data/countries/cn.zone
```
有了國家的所有 IP 地址,要想屏蔽這些 IP 就很容易了,直接寫個腳本逐行讀取 cn.zone 文件並加入到 iptables 中:
```sh
#!/bin/bash
# Block traffic from a specific country
# written by vpsee.com
COUNTRY="cn"
IPTABLES=/sbin/iptables
EGREP=/bin/egrep
if [ "$(id -u)" != "0" ]; then
echo "you must be root" 1>&2
exit 1
fi
resetrules() {
$IPTABLES -F
$IPTABLES -t nat -F
$IPTABLES -t mangle -F
$IPTABLES -X
}
resetrules
for c in $COUNTRY
do
country_file=$c.zone
IPS=$($EGREP -v "^#|^$" $country_file)
for ip in $IPS
do
echo "blocking $ip"
$IPTABLES -A INPUT -s $ip -j DROP
done
done
exit 0
```
好 IP 和壞 IP 都被屏蔽掉了,這種辦法當然不高明,屏蔽 IP 也沒有解決被攻擊的問題,但是是解決問題的第一步,屏蔽了攻擊源以後我們才有帶寬、時間和心情去檢查 VPS 的安全問題。公布一份我們客戶被攻擊的網絡流量圖,在18點到0點所有帶寬都被攻擊流量占用,這時候客戶無法登錄 VPS,訪問者也無法訪問網站:
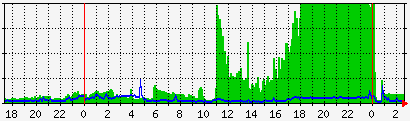
> 原文網址 : https://gitbook.tw/chapters/gitflow/why-need-git-flow.html
當在同一個專案一起開發的人數越來越多,如果沒有訂好規矩,每個人的 Commit 習慣可能都不同,放任大家隨便 Commit 的話遲早會造成災難。
在 2010 年的時候,就有人提出了一套流程,或說是訂了一套規矩讓大家可以遵守:
網址:http://nvie.com/posts/a-successful-git-branching-model
不過因為這套流程是 2010 年提出的,到現在也已經九年了,這幾年來也陸續有其它優秀的開發流程,例如 GitHub Flow、Gitlab Flow 等流程,我們這邊僅以 Git Flow 做為介紹。
### 分支應用情境
根據 Git Flow 的建議,主要的分支有 master、develop、hotfix、release 以及 feature 這五種分支,各種分支負責不同的功能。其中 Master 以及 Develop 這兩個分支又被稱做長期分支,因為他們會一直存活在整個 Git Flow 裡,而其它的分支大多會因任務結束而被刪除。

### Master 分支
主要是用來放穩定、隨時可上線的版本。這個分支的來源只能從別的分支合併過來,開發者不會直接 Commit 到這個分支。因為是穩定版本,所以通常也會在這個分支上的 Commit 上打上版本號標籤。
### Develop 分支
這個分支主要是所有開發的基礎分支,當要新增功能的時候,所有的 Feature 分支都是從這個分支切出去的。而 Feature 分支的功能完成後,也都會合併回來這個分支。
### Hotfix 分支
當線上產品發生緊急問題的時候,會從 Master 分支開一個 Hotfix 分支出來進行修復,Hotfix 分支修復完成之後,會合併回 Master 分支,也同時會合併一份到 Develop 分支。
為什麼要合併回 Develop 分支?如果不這麼做,等到時候 Develop 分支完成並且合併回 Master 分支的時候,那個問題就又再次出現了。
那為什麼一開始不從 Develop 分支切出來修?因為 Develop 分支的功能可能尚在開發中,這時候硬是要從這裡切出去修再合併回 Master 分支,只會造成更大的災難。
### Release 分支
當認為 Develop 分支夠成熟了,就可以把 Develop 分支合併到 Release 分支,在這邊進行算是上線前的最後測試。測試完成後,Release 分支將會同時合併到 Master 以及 Develop 這兩個分支上。Master 分支是上線版本,而合併回 Develop 分支的目的,是因為可能在 Release 分支上還會測到並修正一些問題,所以需要跟 Develop 分支同步,免得之後的版本又再度出現同樣的問題。
### Feature 分支
當要開始新增功能的時候,就是使用 Feature 分支的時候了。Feature 分支都是從 Develop 分支來的,完成之後會再併回 Develop 分支。

平時上班時比較自由,老闆通常都可以容許我們一邊聽著歌一邊工作。所以每坐回位置時第一個動入就是把耳機放到耳朵,然後打開 YouTube 播放著歌曲就繼續工作。有時甚至會沒有播著音樂也會插著耳機。
不知道由那時開始 YouTube已經變成了人們的 Music Player,以前的 Winamp, Window Media Player 的 MP3 歌曲列表已經不合時宜。而現在很多音樂公司在新曲發佈時也是最先在 YouTube上發佈,同時也是不用付費就可以隨時隨地收聽。
### 細心的功能
用上了傳統的純黑色介面來作為介面的主色,令使用者有種來到了電影院的感覺。有一點令筆者覺得十分細心,就是當使用者聽著歌曲時,在 Search Bar 輸入文字找歌曲時,歌曲會一直播放直到使用者按下第二條影片才會跳轉。減少了中間沒有聲音的停頓,也防止了找不到心水歌曲時停了原來的那首歌。
### 付費功能
有了新的音樂專用介面,當然也加入了付費的功能。就是使用者可以加入成為音樂專用帳戶。那麼在聽歌時就不會再有廣告出現中斷影片了。
Currently 19Site is working on a project need to integrate with Google GSuite. This post is for saving some usable link of documentation.
### OAuth2 Service Account
https://developers.google.com/identity/protocols/OAuth2ServiceAccount
### Google OAuth2 scope list
https://developers.google.com/identity/protocols/googlescopes
### Directory API (Admin SDK)
https://developers.google.com/admin-sdk/directory/v1/guides/authorizing
### Calendar API v3 reference
https://developers.google.com/calendar/v3/reference
### What is Google Analytics?
Google Analytics (GA) is a data analysis tools provide by Google. It used to analysis website or app (android / ios). Is the most common data analysis tool in current internet. And it is free.
GA official web site : https://analytics.google.com/analytics/web
### Using GA in React
First we need on add react-ga package into your project :
```sh
npm install react-ga --save
```
Package: https://github.com/react-ga/react-ga
Let's create a new component for Google Analytics :
```js
import React from 'react';
import { withRouter } from 'react-router-dom';
import PropTypes from 'prop-types';
class GoogleAnalytics extends React.Component {
render() {
return ;
}
}
// prop types
GoogleAnalytics.propTypes = {
// provide GA tracking id from props
trackingId: PropTypes.string.isRequired
};
export default withRouter(GoogleAnalytics);
```
Import react-ga to this file :
```js
import ReactGA from 'react-ga';
```
Add a function for notify GA page view action :
```js
updatePageView() {
// read location information from react-router
var url = this.props.location.pathname + this.props.location.search;
// send url to GA
ReactGA.pageview(url);
}
```
Add code to `componentDidMount` for initial react-ga module :
```js
componentDidMount() {
// initial react-ga module
ReactGA.initialize(this.props.trackingId);
// update page view (when first loaded)
this.updatePageView();
}
```
Add code to `componentDidUpdate` to handle URL change event :
```js
componentDidUpdate(oldProps) {
// old url
var oldUrl = oldProps.location.pathname + oldProps.location.search;
// current url
var currentUrl = this.props.location.pathname + this.props.location.search;
// url changed
if( oldUrl !== currentUrl ) {
// update page view
this.updatePageView();
}
}
```
The final file (GoogleAnalytics.js) output :
```js
import React, { Component } from 'react';
import { withRouter } from 'react-router-dom';
import PropTypes from 'prop-types';
import ReactGA from 'react-ga';
/**
* google analytics
*/
class GoogleAnalytics extends Component {
/**
* component did mount
*/
componentDidMount() {
// set ga id
ReactGA.initialize(self.props.trackingId);
// update page view
this.updatePageView();
}
/**
* component did update
*/
componentDidUpdate(oldProps) {
// old url
var oldUrl = oldProps.location.pathname + oldProps.location.search;
// current url
var currentUrl = this.props.location.pathname + this.props.location.search;
// url changed
if( oldUrl !== currentUrl ) {
// update page view
this.updatePageView();
}
}
/**
* update pageview
*/
updatePageView() {
// url
var url = this.props.location.pathname + this.props.location.search;
// update page view
ReactGA.pageview(url);
}
/**
* render
*/
render() {
return ;
}
}
// prop types
GoogleAnalytics.propTypes = {
trackingId: PropTypes.string.isRequired
};
// export
export default withRouter(GoogleAnalytics);
```
### Adding GoogleAnalytics to project
To let GoogleAnalytics works, you need to add an instance as a child under `` component :
```js
import GoogleAnalytics from './components/GoogleAnalytics.js';
```
```js
render() {
}
```
### Check result
Once your GA setup completed. When you switch page over you site. Your GA current you should be update appropriately.

By using shell scripting, user may automate the process of download and install phpMyAdmin. One thing you setup phpMyAdmin is copy the `config.sample.inc.php` to `config.inc.php` and change the blowfish secret value to a random string.
### command : sed
You may use `sed` command to search and replace string in a file. And using `openssl` to generate a random string.
```sh
sed -i -e "s|\$cfg\['blowfish_secret'\] = ''|\$cfg['blowfish_secret'] = '$(openssl rand -base64 32)'|g" ./config.inc.php
```
The command shown above is an example of `sed` command to generate a random as the blowfish secret value.
### Full sample
Codes below is the full sample for download phpMyAdmin from official web site and extract to machine.
```sh
#! /bin/sh
wget -O /opt/pya.zip https://files.phpmyadmin.net/phpMyAdmin/4.9.0.1/phpMyAdmin-4.9.0.1-all-languages.zip
unzip /opt/pya.zip -d /opt
rm /opt/pya.zip
cp /opt/phpMyAdmin-4.9.0.1-all-languages/config.sample.inc.php /opt/phpMyAdmin-4.9.0.1-all-languages/config.inc.php
sed -i -e "s|\$cfg\['blowfish_secret'\] = ''|\$cfg['blowfish_secret'] = '$(openssl rand -base64 32)'|g" /opt/phpMyAdmin-4.9.0.1-all-languages/config.inc.php
```
Some time you may want to access to user information from their google account (e.g. Calendar, Email, etc... ). To do so, you first have to create a project on Google API Console and setup OAuth settings.
### Create a new project for you application
Create a test project on Google Cloud Platform (Google API Console)
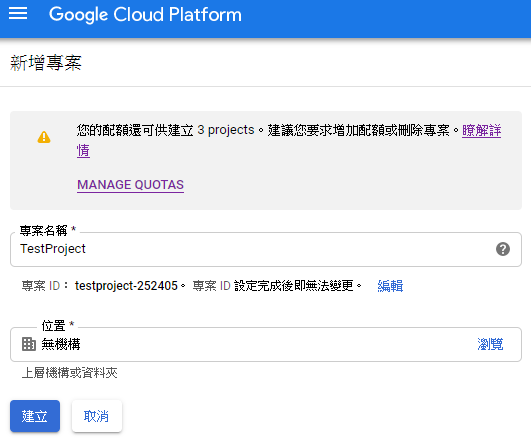
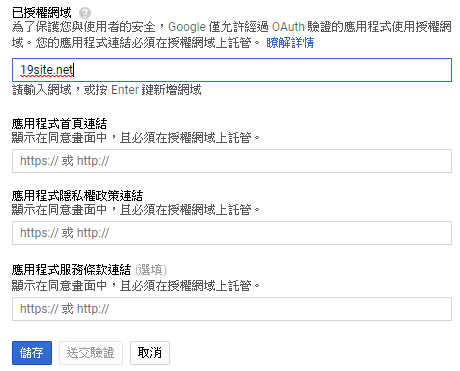
### Setup OAuth 2.0 authorize page
Select API and Service

Fill your application name

Fill in you direct URL. (OAuth2.0 need a URL to redirect back to your site form passing the token or code)
### Setup OAuth 2.0 application client
You have to create an OAuth 2.0 client in order to make it work.
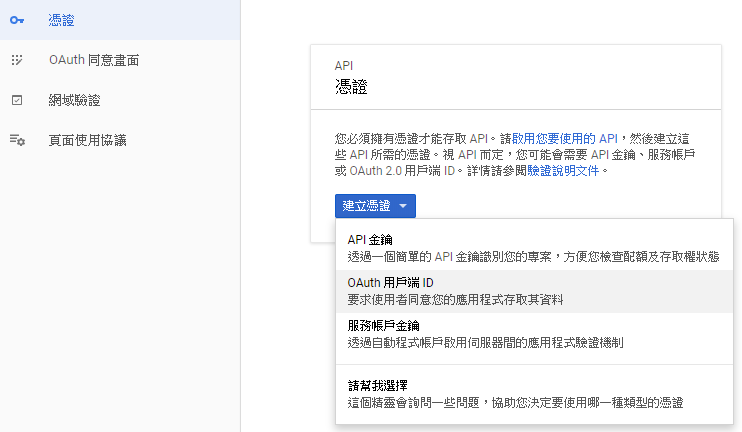
Select application type and fill your web site url. (redirect url)
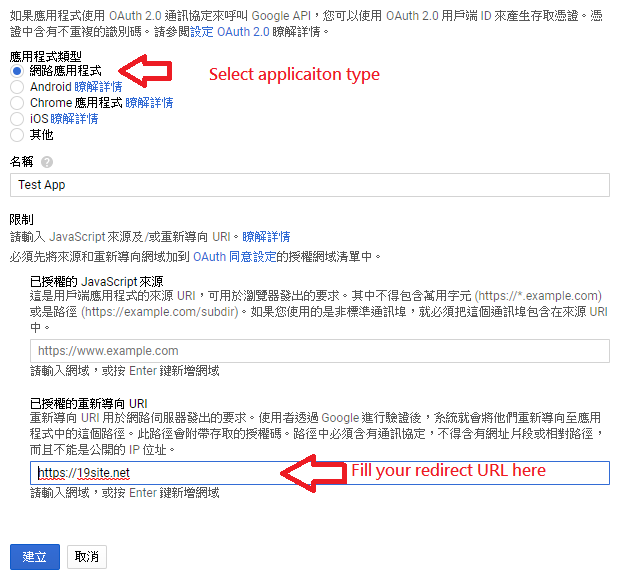
Then you will receive a OAuth2.0 client id and secret key.
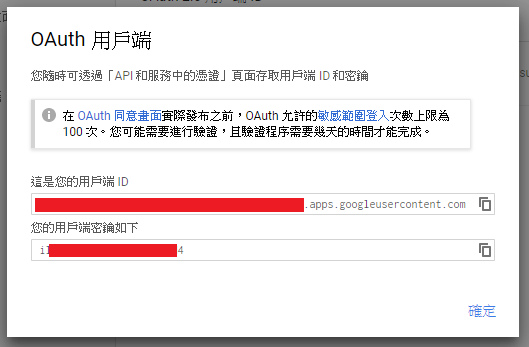
That's all of Google part setting.
### Your application
Reference URL : https://developers.google.com/identity/protocols/OAuth2WebServer
In you application, application may generate a URL to Google OAuth 2.0 server and redirect the user there.
Code below is a example in NodeJs.
```js
var query = Qs.stringify({
scope: 'https://www.googleapis.com/auth/calendar',
access_type: 'offline',
include_granted_scopes: true,
state: 'state_parameter_passthrough_value',
redirect_uri: 'https://19site.net',
response_type: 'code',
client_id:
});
var url = 'https://accounts.google.com/o/oauth2/v2/auth?' + query;
```
The URL will prompt user to select their Google account to continue.
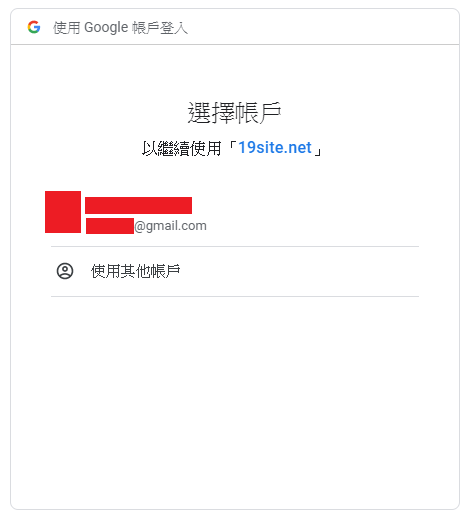
Ask you user to grant the following permission to your application.
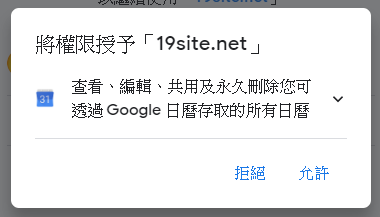
Confirm user action.
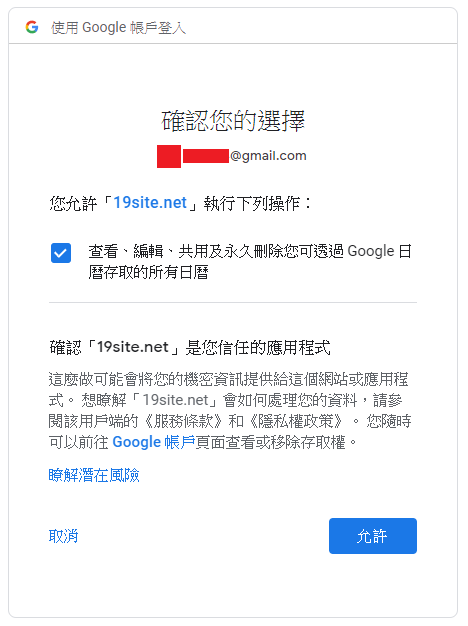
Then user will redirect to the URL that you set (https://19site.com).
Finish : )
### 淺草
第二天的行程是淺草,這天是星期六。剛好是日本四大祭的其中一天,這天會有大型的燈火活動,所以在先前準備行程時安排了這天到淺草參觀,同時也編排了穿日本浴衣的活動。
早上出門後,我們什麼也沒有吃就直接出發到淺草。由池袋區坐地鐵去也要很長的時間。

')


吃飽後我們就到了剛剛照片那家浴衣店去了。誰知道那家浴衣店原來在淺草區有超多分店的 !!! 我們預訂的那一家是在別的地點 !! (先前也有聽過後多遊客也會遇過這個情況)
經過我們和店員的一輪身體語言和道路教學後,終於找到了我們預訂的那家店了。門面是超多人排隊的呢 !!!
內裡的客人超多,大部份都是本土的年輕男女,可能是有祭典所以都有機會約會他們的伴侶穿浴衣一起賞花火。
店內分上下兩層,下層是結帳及男士換衣服的。而二樓是給女士專用的選衣間及化妝間。由於男士的比較簡單,所以筆者先在下層的位置選了浴衣便去換衣了。會有專人幫助你去換衣服,所以不用怕會不懂得穿。幫助換衣服的是個女士,換衣時會脫淨內褲,她會幫你處理好一切。
當我換好後同行的兩位女士還在坐著沒動,原來是因為女生太多了,所以需要再等多一會時間才能選浴衣。最後差不多要一個半小時後才能全部完成外出活動。埋單 17,000 日圓 ( 2 女 1 男 )。







我們是預定大家下午 5 時半前回到店家還衣服的,不過天氣實在太熱了。行到大約4 時已經很累,所以大約 4 時半就回到店家去還衣服,然先去吃個凍甜品 !!! 真的超爽。再去吃了個迴轉壽司補充體力,準備晚上去看花火大會。
日本的看煙花人流管制做得不錯,大群可以進到大馬路去向花火方向的河進行花火觀賞。人流只可以向前進且不能停留,同一時間煙花也會分階段慢慢的放。所以人流都會有機會能走到橋上近距離看到花火,真的很不錯的體驗。


過穚後原來在穚的另一方已經有大型的封路安排,並在馬路上設有區段供市民可以坐下來賞花火。而我們就走往最近的地鐵站坐地鐵回池袋。

回到池袋已經很累,但是因為草姐後天便會回去,所以我們也到了東口的激安血併了一輪 !!! ( 當然少不了到東口後街夾公仔 )
### 東京
一個我從來沒有踏足過的地方,從以前不能去日本旅遊 (因為褔島核事故安全問題),到現在最近三次旅遊目的地都是日本 ! 開始明白為什麼人們喜歡到日本旅遊了 ! 因為真的好好玩好方便 !!!
那天是乘坐早上機的 (大約十一時),但是飛機遲了起飛,大約差不多遲了一個小時。到達成田機場時已經進入黃昏了。


')
到了池袋天色已經黑齊了,我們急急找到了酒店放下行季後,便下樓找吃的東西。

太累了,吃飽了東西後就到附近的 7-11 買了些少零食後就回酒店休息了。
Sometime you may want to insert a `tab` character (for indent) in a `textarea` element. By default when user hit the `tab` key the current focus element will move to the next element.
### Add a \t into your current position
By insert a `\t` character right after the current cursor position
```js
// target element
$('#my-textarea').on('keydown', function(evt) {
// get the key code
var keyCode = evt.keyCode || evt.which;
// tab key
if (keyCode == 9) {
// prevent default action of key down
evt.preventDefault();
// get the textarea DOMElement
var textarea = this;
// get the value of textarea
var value = $(textarea).val();
// get the cursor current position
var start = textarea.selectionStart;
// get the cursor selection end position (if there some text selected)
var end = textarea.selectionEnd;
// string before start position
var start_string = value.substring(0, start);
// string after end position
var end_string = value.substring(end, value.length);
// insert string
var insert_string = '\t';
// insert the insert string between string string and end string
var new_value = start_string + insert_string + end_string;
// set a new value to textarea
$(textarea).val(new_value);
// set the cursor position right after the string just inserted
textarea.setSelectionRange(start + insert_string.length, start + insert_string.length);
}
});
```
### What is Drag and Drop?
Drag and drop is a event to handle user mouse action. Drag any thing into an area (e.g. `<div>`) will fire appropriate events.
There are 4 events you have to handle:
1. dragenter
2. dragleave
3. dragover
4. drop
### Event: dragenter
This event will file when user drag anythings into the target area. Only fire when entering the DOMElement.
### Event: dragleave
This event will file when user drag anythings out the target area. Only fire once when leaving the DOMElement.
### Event: dragover
This event will file when user drag anythings onto the target area. Event will keep firing when mouse dragged something and moving over the target area.
### Event: drop
This event will file when user drop anythings into the target area. Only fire once when dragging items dropped into the DOMElement.
### Add event listener to DOMElement
The following code shows how to add event listeners to those events:
```js
var div = document.getElementById('my-div');
div.addEventListener('dragenter', evt => {
// do something
});
div.addEventListener('dragleave', evt => {
// do something
});
div.addEventListener('dragover', evt => {
// do something
});
div.addEventListener('drop', evt => {
// do something
});
```
The above sample is for standard javascript with jquery.
### Do in React way
In react, you may use `ref` to accomplish this.
```js
class YourDragAndDropComponent extends Component {
dropRef = React.createRef();
constructor(props) {
super(props);
this.state = {};
this.onDragEnter = this.onDragEnter.bind(this);
this.onDragLeave = this.onDragLeave.bind(this);
this.onDragOver = this.onDragOver.bind(this);
this.onDrop = this.onDrop.bind(this);
}
componentDidMount() {
const div = this.dropRef.current;
div.addEventListener('dragenter', this.onDragEnter);
div.addEventListener('dragleave', this.onDragLeave);
div.addEventListener('dragover', this.onDragOver);
div.addEventListener('drop', this.onDrop);
}
componentWillUnmount() {
const div = this.dropRef.current;
div.removeEventListener('dragenter', this.onDragEnter);
div.removeEventListener('dragleave', this.onDragLeave);
div.removeEventListener('dragover', this.onDragOver);
div.removeEventListener('drop', this.onDrop);
}
onDragEnter(event) {
// todo
}
onDragLeave(event) {
// todo
}
onDragOver(event) {
// todo
}
onDrop(event) {
// todo
}
render() {
return (
);
]
}
```
新版的 GOOGLE SITE 的確是一個強勁的東西!
可以好像做 PPT 一樣,就可以完成一個網站了。還會自帶有 responsive 功能,雖然比起舊版會有較多排版上的限制 (因為要預留 responsive 的空間),但是輕輕幾下就可以製作出十分耀眼的網站!
這裡做了一個 [Demo Site](https://sites.google.com/view/pet-cloud) ,大約用了 2 個小時左右。
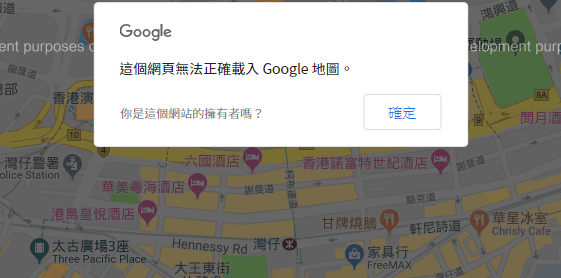
不知道可時開始 GOOGLE MAP 已經收費了,大概是在大半年前有客戶的網站內,GOOGLE MAP 彈出了 "這個網頁無法正確載入 Google 地圖。" 這句說話。當時也沒有太大的理會!時至今日那個客戶的網站依然是掛著這句說話在 GOOGLE MAP 上,他也好像不太想理會了!可能是因為地圖只會用在聯絡我們上!
↓ 雖然有這個說話彈出來,但是所有的功能是依然能正常運作的,在背景上多了 "for development purposes only" 字樣。
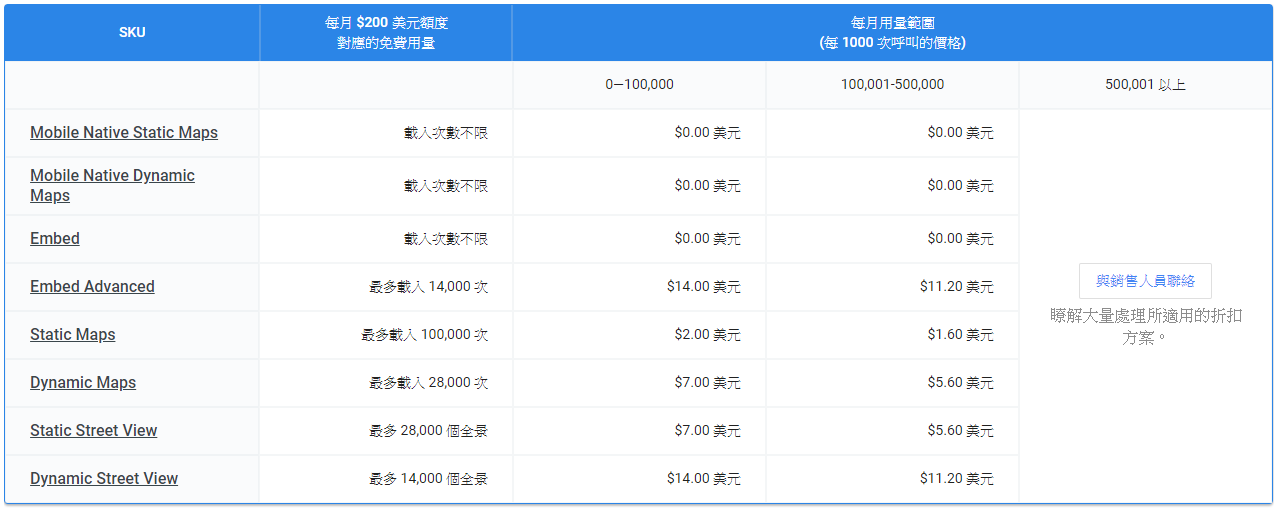
定價方案 :
https://cloud.google.com/maps-platform/pricing/sheet
↓ 每個月有 $200 美元的免費使用額度,超過了便會開始收費!(算是佛心?)

在名古屋的一所扭蛋店裏居然找到了公主系列的扭蛋!當然不能錯過要扭幾個回來!!!
雖然找不到白雪公主的扭蛋 (真是可惜),不過愛麗絲也是絕對值得入手的!













這個公主系列的扭蛋在香港的現時點賣到 $90,貝兒的 $100+,受喜愛程度十分高!
在香港如果要去機場的話,我們可以選擇巴士、港鐵及的士,當中時間最穩定一定是港鐵。但前提是你出發的地點是近港鐵站。但是坐港鐵來回機場也不便宜,單程青衣到機場已經要 60 元,但是其實有方法可以買到更平的車票的!以下會講解一下小弟試過的方法。
我們乘坐港鐵的時候通常也會在售票處先購買車票,然後使用車票乘搭港鐵。但是如果乘坐機場快線的話,我們是可以先到旅行社購買來回的套票,一般都會比在港鐵售票處買的便宜。
另外如果你有 wechat 的話,那麼便可以直接在 wechat 的錢包內購買機場快線車票,流程十分簡單。只要你在錢包內選擇交通,然後選擇機場快線車票,選擇出發的地點及日期,便可以使用 wechat 錢包付款。付款後會有確認的電子郵件寄到你的電郵信箱,電郵內會包含一組二維碼,該二維碼是用來入閘時使用的,wechat 的交通套票是由 klook 包辦的,所以不用擔心。到了港鐵的閘機,只需要打開電郵的二維碼放到入閘機的素描器上,使可以過閘。




Nothing is better than rewrite from sketches, Its does not need to handle old staff.
Last year, my first blog started using Google Blogger. I had modify a lot of XML to customize the layout to fit my needs. It is possible to do many things on Blogger by still a lot cannot. After invent so much time on it, I started write a Blog CMS using Laravel (PHP). It is funny and easy to make anythings fit my idea.
I added a code editor into CMS so that I can customize each post... But this is a bad idea apparently. haha. I am too lazy to write every post in html code. Finally the blog leave abandoned about half year...
( This blog using Markdown to write post )
Recently I wanted to try some new thing (thing is not new but I never used before). So I choose Koa + React to revamp the old blog again. Hope every thing is OK : )
## What is React?
A JavaScript library for building user interfaces.
https://reactjs.org
React is a Javascript library develop by Facebook. It is a frontend library help developer to build UI components.
## What is Markdown?
Markdown is a type of syntax that format your text context to display HTML appropriately.
[Markdown-Cheatsheet](https://github.com/adam-p/markdown-here/wiki/Markdown-Cheatsheet)
This is a Markdown document demonstrate the syntax and result.
> 原文網址 : https://blog.csdn.net/zbw18297786698/article/details/54349046
在項目中驗證 SQL 語句執行效率的時候最直觀的方式就是查看其執行時間,但是在線上環境中如果不慎運行一個效率十分低下的 SQL 導致數據庫當掉了,那就悲劇了。並且只看執行時間,並無法有效的定位影響效率的原因。因此通過 `EXPLAIN` 命令查看SQL語句的執行計劃,根據執行計劃可以對SQL進行相應的優化。理解SQL執行計劃各個字段的含義這時候顯得十分重要。
如下圖
```sql
EXPLAIN SELECT COUNT(*) FROM blog
```

這是一個簡單的 SQL 的執行計劃,可以看到其包含十個字段來描述這個執行計劃。
其中比較重要的字段有 `select_type`、`type`、`ref`、`extra` 。
下面為更好的理解執行計劃,這裡對每個字段進行相應的解釋。
### id
一個複雜的sql會生成多執行計劃如下圖:
```sql
EXPLAIN SELECT COUNT(*) FROM (SELECT id from blog where id = 1) a
```

可以看到含有子查詢的sql產生了兩條記錄,分別表示該條sql的執行順序。
### select_type
查詢類型,有如下幾種值
1. simple 表示簡單查詢,沒有子查詢和union 如圖1所示
2. primary 最外邊的select,在有子查詢的情況下最外邊的select查詢就是這種類型如圖2所示
3. union union語句的後一個語句執行的時候為該類型如圖2.1所示
```sql
EXPLAIN SELECT COUNT(*) FROM blog UNION SELECT id from blog where id = 1
```

union result union語句的結果如圖所示。
### table
使用的表名
### type
連接類型,十分重要的字段 按照代表的效果由最優到最差情況進行介紹。
#### system
表僅有一行 const的特例。
#### const
最多匹配一行並且使用 `PRIMARY KEY` 或 `UNIQUE` 索引,才會是 `const`。
```sql
EXPLAIN SELECT * FROM blog where id =1
```

下面這種情況搜索到一條數據但是沒有用到主鍵或索引 所以 type 不是 `const` 關於all的含義將在下文介紹
```sql
EXPLAIN SELECT * FROM blog LIMIT 1
```

#### eq_ref
根據 MYSQL 官方手冊的解釋: "對於每個來自於前面的表的行組合,從該表中讀取一行。這可能是除了 `const` 類型最好的聯接類型。它用在一個索引的所有部分被聯接使用並且索引是 `UNIQUE` 或`PRIMARY KEY`。 `eq_ref` 可以用於使用=比較帶索引的列。看下面的語句
```sql
EXPLAIN SELECT * FROM blog, author where blog.blog_author_id = author.id
```

```sql
EXPLAIN SELECT * FROM author, blog where blog_author_id = author.id
```

#### ref
對於所有取自前表的行組合,所有的匹配項都是通過索引讀出的。也可以理解為連接不能基於關鍵字選擇單個行,可能查找到多個符合條件的行。叫做 `ref` 是因為索引要跟某個參考值相比較。這個參考值或者是一 個常數,或者是來自一個表裡的多表查詢的 結果值。
如下圖
```sql
EXPLAIN SELECT * FROM blog where blog_author_id = 2 // 其中blog_author_id有索引
```

寫到這裡 相信大家還是對以上各種類型的解釋有點迷迷糊糊。下面看一個等值連接的例子,會加深對索引和以上解釋的理解。
```sql
SELECT * FROM author, blog where author.id=blog.blog_author_id and author.id = 2
```
這條語句查出作者2發表的所有博客。 id為author表主鍵,mysql會自動為主鍵創建唯一索引。而blog_author_id是blog一個普通字段,如果對其加個索引看一下運行的效果。

先觀察下一下這個執行計劃,可以看出 MYSQL 對 SQL 語句的執行已經做了很好的優化.這裡可以看到其中一條優化規則,先做選擇操作縮小連接操作的集合維度,再做連接操作,詳細可查看 MYSQL 生成執行計劃的優化策略。
解釋一下:第一行代表 MYSQL 生成的第一個執行計劃。即 `select * from author where id= 2` 由於 `id` 是 `author` 表的主鍵,且表包含多條數據但僅命中一行,所以其類型為 `const`。
第二行:對於 `blog` 表中 `auhorid` 為 2 的記錄有多個,且是通過索引讀出的。滿足 `ref` 的條件。
自然而然 如果把 `blog` 表中的 `author_id` 所以去除掉,則其類型應該不會再是 `ref`。讓我們來驗證這個想法。
```sql
drop index author_id on blog
```
再來執行以下查詢語句

可以看到 `type` 類型變為 `ALL` 了,這種類型的效率非常慢,同時你可以看到 rows 這一行數據也發生了變化。由於沒有索引,所以需要掃描全表。詳細關於 `ALL` 類型和 rows 列的含義將在下文中介紹。
下面接著看下一個類型。
#### ref_or_null
如同 ref,但是添加了 MySQL 可以專門搜索包含 NULL 值的行。在解決子查詢中經常使用該聯接類型的優化。或解釋為MySQL 必須在初次查找的結果 裡找出 null 條目,然後進行二次查找。
這種類型沒搞明白 做實驗都沒出現這種類型 希望各位朋友給個例子。
但是上面說的這五種類型是屬於總體來說效果很不錯的了。如果能滿足以上類型的查詢 基本上不需要太大的優化、下面介紹效率較低幾種類型 當出現以下幾種類型的查詢 就要好好考慮做做優化了。
#### index_merge
該聯接類型表示使用了索引合併優化方法。在這種情況下,key列包含了使用的索引的清單,key_len包含了使用的索引的最長的關鍵元素。查看下面這條sql
```sql
EXPLAIN SELECT * FROM blog where blog_title = "first" and blog_author_id = 1
```

大致解釋一下索引和並優化的概念,這時mysql針對sql使用多個索引進行查詢時的優化方案。通俗的說就是mysql會把同一個表的多個索引掃描的結果進行合併。詳細的去看看相關博客。
解釋一下上述的例子,分別對blog_title和authorid創建索引,這時用and查詢滿足以上兩種條件的結果,如果查到一條的話它就是ref 但是如果匹配多條的話他就會進行索引合併。
#### unique_subquery
顧名思義 subquery可以看出這種類型跟子查詢有關係,同時大家知道子查詢在mysql中是十分不建議使用的一種查詢方式,當遇到子查詢時多思考如果通過連接查詢來優化。盡可能少的使用IN語句。
在某些 IN 查詢中使用此種類型,而不是常規的 ref:value IN (SELECT primary_key FROM single_table WHERE some_expr)
```sql
EXPLAIN SELECT * FROM blog where blog_author_id in (SELECT id from author where author_name = 'test1')
```

即使對 authorname 創建索引也是相同的執行計劃
對於這種情況你可以將其改寫成一個 left join 語句
```sql
SELECT blog.* FROM blog LEFT JOIN author ON blog_author_id = author.id WHERE author_name = 'test1'
```
一樣的執行結果 但是執行計劃就是不同的如下圖

可見這種查詢就是用到了索引。效率可想而知。
#### index_subquery
在某些 IN 查詢中使用此種類型, 與 unique_subquery 類似,但是查詢的是非唯一性索引:
```sql
value IN (SELECT key_column FROM single_table WHERE some_expr)
```
```sql
EXPLAIN SELECT * FROM author where id in ( SELECT blog_author_id from blog where blog_title = 'secend')
```

同樣的要盡量避免使用這種方式的查詢。
### range
顧名思義,range意思就是范圍。因此可以解釋為:只檢索給定範圍的行,使用一個索引來選擇 行。 key 列顯示使用了哪個索引。當使用=、 <>、>、>=、<、<=、IS NULL、<=>、BETWEEN 或者 IN 操作符,用常量比較關鍵字列時,可 以使用 range。
這種類型解釋的很清楚了 稍微舉個栗子大家看看吧。
```sql
EXPLAIN SELECT * FROM blog where id > 2
```

#### index
這種類型的意思也十分明顯,查詢過程中使用到了索引。解釋為: 全表掃描,只是掃描表的時候按照索引次序 進行而不是行。主要優點就是避免了排序, 但是開銷仍然非常大。舉個栗子
```sql
EXPLAIN SELECT * FROM blog ORDER BY id
```

#### all
最壞的情況,從頭到尾全表掃描 。性能最差的一種類型 遇到這種類型 你得想想 為什麼不建索引!為什麼 不改造 sql!改造sql也是為了讓mysql運行的時候盡可能的使用到索引, 這裡又牽扯出一個問題 如何建索引 數據庫維護索引也是一件十分費時費力的事情。詳細內容自行查詢 本人還未總結~~~
這個就不舉例子了 大家看看上邊的例子 有很多連接查詢計劃中都存在all類型,順便想想如何優化。
解釋到這里大家對執行計劃所代表的效率含義基本上有個認識了,現在對後面的字段進行介紹。
### possible_keys
很明顯了 它的意思就是有可能使用到的索引。
### key
MySQL 實際從 possible_key 選擇使用的索引。如果為 NULL,則沒有使用索引。很少的情況 下,MYSQL 會選擇優化不足的索引。這種情 況下,可以在 SELECT 語句中使用 USE INDEX (indexname)來強制使用一個索引或者用 IGNORE INDEX(indexname)來強制 MYSQL 忽略索引。
### key_length
使用索引的長度。當然在不失精度的情況下 長度越小越好!
### ref
顯示索引的那一列被引用到了。
### rows
MYSQL 認為必須檢查的用來返回請求數據的行數,越大越不好。說明沒有很好的使用到索引。
### Extra
表示mysql解決查詢的詳細信息。
#### Using Index
表示使用到索引
#### using filesort
表示 MySQL 會對結果使用一個外部索引排序,而不是從表裡按索引次序讀到相關內容。可能在內存或者磁盤上進行排序。 MySQL 中無法利用索引完成的排序操作稱為“文件排序” 常見於 order by 和group by語句中。注意如果你對排序列創建索引mysql仍然會提示你使用的是filesort,所以對於這個字段應該有自己的判斷。
```sql
EXPLAIN SELECT * FROM blog order by blog_title
```

#### Using temporary
表示進行查詢時使用到臨時表。當使用到臨時表時,表示sql的效率需要進行相應的優化了。這種類型可能會在連接排序查詢中出現。
為了便於理解先舉一個例子。
```sql
EXPLAIN SELECT * FROM author,blog where author.id=blog.blog_author_id and blog.blog_title='first' order by author.id desc
```

這條語句是要查出寫first這篇博客的博主信息,並按用戶id排序。
先來看看mysql連接查詢算法 Nested Loop Join 通過驅動表的結果集,一條一條的按照連接條件查詢下個表中的記錄。
這裡出現了一個名詞 驅動表
驅動表定義:
1. 當連接條件確定時,查詢條件篩選後記錄少的為驅動表。
2. 當連接條件不確定時,行數少的表為驅動表。
按照上述定義,由於blog_tiltle經過篩選條件後查詢得到的記錄數為2,而未對author表進行條件過濾,因此該sql的驅動表為blog。
將過濾後的blog表的記錄一條條的對author表查詢,而後合併,這時需要按照author表的id字段進行排序,因此需要對合併結果(臨時表)進行排序。
如果按照驅動表排序,則可以直接排序而無需臨時表。
```sql
EXPLAIN SELECT * FROM author,blog where author.id=blog.blog_author_id and blog.blog_title='first' order by blog.id desc
```

Any system authorized by user and password is possible hacked by password dictionary hacking. So we need to define some rule to identify who is hacking your system and who is not. We usually use retry times to identify this. When a user entered wrong password for 'N' times. System will do some action (by blocking IP address or disabled the user for a few hours) to prevent password retry many times. And here is a nice software to provide this service.
### fail2ban
Fail2ban is a software that will parse (most common) application log files. When continuous error found. Fail2ban will setup a rule on firewall to block the access from target IP address. Aim to protect your system from unauthorized access.
### Install
You may run the following commands to install fail2ban to your system.
```sh
$ sudo apt-get update
$ sudo apt-get install fail2ban -y
$ sudo service fail2ban start
```
For more information please visit :
[fail2ban official site](https://www.fail2ban.org/wiki/index.php/Fail2Ban)
### Why you need to disable root login from SSH?
Allow root login from remote server is danger and it is no recommended. Because root account has the highest privilege to modify the whole system. You may replace root login by using `SUDO` command with `SUDO` enabled users or login to SSH by using SSH Key.
### How to disable root login
We can follow the steps below to disable root (or specified user) login via SSH:
Step 1. Edit /etc/ssh/sshd_config
```sh
$ vi /etc/ssh/sshd_config
```
Step 2. Find the following line and set the value to `no`
```sh
PermitRootLogin no
```
If you want to disable specified user, you may change the following line:
```sh
DenyUsers USERNAME
```
Step 3. Restart SSH service
Finish !
### View system distribution
```sh
$ cat /etc/*release
```
### Check memory state
```sh
$ free -mh
```
## Check system state
```sh
$ top
```
### View file system
```sh
$ df -h
```
### List system running process
```sh
$ ps aux
```
filter by keyword
```sh
$ ps aux | grep
```
### List system listening port
```sh
$ netstat -tlnp
```
### Extract .tar.gz file
```sh
$ tar zxvf
```
### Compress a file / folder to .tar.gz
```sh
$ tar zcvf